Pitching a hack (or a product) do’s and dont’s
Saturday, May 16th, 2009Disclaimer: Dearie me, some of this is very subjective and may completely disagree with what worked for you. This is great and please leave a comment about what worked and what tips you can give rather than shooting one of the points here down in flames. I simply listed what I was looking for and what worked well for me in the past.
We just came back from the University hack day in Sunderland, England where students pitched hacks they built in a few weeks to judges that were meant as mock clients. As students asked us for feedback on what went well in the presentations and what didn’t here are some tips and tricks.
Pitches are not sex – you don’t need foreplay
The first mistake almost every group made was to introduce who they are and what they used to make the hack. This was partly a requirement of the assessment but it is also a sure-fire way to bore judges or VCs. There are two ways you can go:
- Show your hack and what it does and then go into the details or
- Explain the one problem that your hack solves and show the hack immediately afterwards as the solution.
Either approach has to answer some questions right off the bat:
- What does the hack do?
- Why should I use it?
- Who is it for?
- What does it do better/different than other solutions?
On being a team
The hack teams were 6-7 people each. Introducing each and every one of them costs a lot of precious time that you cannot use to make the audience interested in your product. Introduce only the needed people – those who will give the pitch and tell after the presentation who else did what in case there are specialist questions that need answering.
Anybody who is not part of the immediate pitch should not be standing around – all they do is distract from the presentation. Absolute suicide is to have people standing on the side scratching various body parts or looking at the ceiling or out of the window. If you pitch as a team, everybody should be awake and damn excited about the product – else you’re doing a better job sitting on the bench.
Your main spokesperson should be the most excited about the product. There were a few presentation wheres the first pitcher was amazing and had us going and when handing over to the tech guy to explain the product snoozing kicked in. If you hand over from presenter to presenter keep the energy flowing, otherwise don’t hand over.
If you have different experts delivering different parts of the pitch have them introduce each other and have their expertise be a natural part of the flow of the presentation. Some teams did a great job at that, with simple sentences like “in the future this will be extended to become important for more audiences and my colleague XY will show you what we have planned on the business side of things.”
On running your presentation
You are the presenter which means that you define the pace of the presentation and which slides are shown. You cannot have somebody else as your slide-jockey – it is terribly unprofessional to have to tell somebody to change the slide or even worse go back some slides. Presenter remotes are not expensive and most places will have some for installed equipment so use these instead. Your focus as the presenter is on the audience or jury and eye-contact is terribly important.
This applies to longer presentations, too. You can find out a lot from the audience reactions. When I present to a big crowd, one trick is to pick out a new single person in the audience I talk directly to every few slides. This is especially good to do if you pick people that seem to drift away and ask yourself what is the “what is in it for me” for that person.
Slides are an aid – not your pitch
One of the rookie mistakes is to have slides that tell and spell out everything you want to say. Less is more – much more. One word could be enough if it is backed up by your presentation. You can and should have a handout that explains details but this should not be your slide deck. Screenshots are good in case the wireless forsakes you – which it always does. Random clipart is bad as the 80ies are definitely over. Humour works – I loved for example typical English self-deprecation when one of the presentations introduced students as a target audience with a student wearing a traffic-cone hat as the example photo.
See your slides as the table of contents of your presentation – not the transcript and definitely not a different story. When your talk deviates from what is written on the wall you’ve lost us.
Bullet points are effective but also have become almost a cliche for presentations. If you feel comfortable with them, by all means use them but never have more than 3-5 on a slide with one short sentence for each.
You learn presentation writing by looking at successful presentation decks. A great resource is SlideShare where people upload their decks and the comments and views show you which ones are successful. My own slides there are all licensed with Creative Commons, which means that I am happy for you to re-use them.
Basic, really very basic typography
This applies to both the slides and the product itself. Legibility and professional type layout is very important. This is not because we are anal about this (and believe me there are a lot of people on the web that are) but there is a subconscious unease when we read things as humans and get lost because there is something not right with it.
Comic Sans Serif was lately added to the Geneva convention as a forbidden weapon when dealing with audiences that are above 3 years of age or don’t suffer from learning disabilities (this is not an evil jib – Comic Sans really proved to be very effective for these groups). Other than that pick a friendly, easy to read font that shows you mean business.
Bullet points should never be center aligned on the screen, unless they are a centered block.
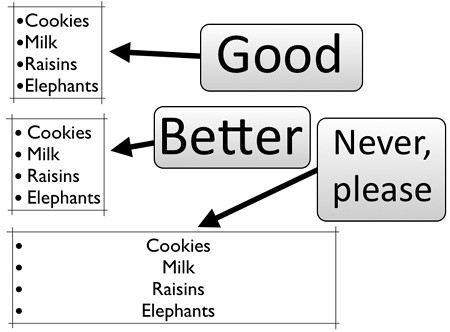
Use a large enough font size and good contrast of background and foreground to keep your slides and products readable even on a terrible projector. Don’t rely on colours to be shown the way you expect them to be.
On web applications, nothing spells “we are unprofessional” more than not defining a font for your text. Out of the box browsers render in Times New Roman, so you just look sloppy if you don’t change that.
If you have no clue about HTML and CSS and you don’t want to bother with it but show something that is readable and works across all browsers, use the YUI grids in your document:
HTML PUBLIC “-//W3C//DTD HTML 4.01//EN”
“http://www.w3.org/TR/html4/strict.dtd”>
My awesome App
My awesome App
I rock! I really do
© by me, thievses!
This adds a very basic level of typography for free and with the CSS hosted (and, if needed, fixed) by Yahoo for you.
Explain the unique – not the very obvious
What you want to achieve with a pitch is to get us excited and interested about what you did. The only real way to do that is to tell us what your system does differently than others – “what is it that makes it unique?” is the question you need to answer.
Get the one thing that makes your product great and shine the world’s biggest light on it.
Do not tell us that you have a delete, update and edit button. Do under no circumstances show us what happens when you click the delete button and – oh wonder of wonders – it deletes something. Then please do not continue to tell and show us the other – as predictable – functionality. Do tell us when one of these functionalities deviate from the normal patterns and do a better job though.
Do not tell us what colours you used in the background, we can see that and the colour is a means to an end, not the main reason to build the hack. Time is precious, do not waste it on things that we can find out for ourselves.
Cover the big concerns
Two things drive people nuts on the web: lacking security and hard to use products. If you ask for data show that you protect that data (some teams did a great job doing that, thanks). If you claim your interface is easy to use, don’t get lost trying to show it and under no circumstance tell other people who show the product for you what to do. “No, click the other button, no the other above this one” does not spell “millions of users will have a great time using this”.
People get annoyed very quickly if things take too long on the web. We use computers and online systems to make our lives easier, not to wait for your system or go through a five step process that could be one. Some teams did a great job with this. Sentences like “you don’t need to sign up, only when you want extra functionality explained here” are a real winner!
Tell the human story
What you build is there for humans. It is great if it makes their lives easier, it is good when it allows them to learn something and it is even OK when it just amuses them for a short while. Don’t get stuck with the technology but find the human aspect of your product instead.
Tell the story of the mother who hasn’t got enough time to juggle the day to day caring for her kids and the hard to use school enrollment and booking system. Tell the story that you got lost and tried hard to find the nearest bus stop and would have loved to get your mobile out and find it. Tell the story that you were not able to enjoy a party as you had no clue when the last train ran so you couldn’t relax as you didn’t want to get marooned there.
Computers are bastards
Things will go wrong in your presentation and you should swiftly deal with that and move on. Most presenters did that. Immediately say what happens normally and move on to the next integral part that works. Even better is when your product shows a great, well worded and easy to understand error message. Failure is as normal as success in software – both cases need a good user interface and not leave the user puzzled what is going on.
Do not try to gloss over
If you get caught out not having thought of something – own up and thank people for the great suggestions. Do not try to skirt around the issue and say that this is in there but you can’t show it now or something like that. Do not make something look as if it is more than it is – with web products it is far too easy to catch you out. Explain why things got omitted and there is no problem with that.
Don’t pad, build one thing well and sell this one
One thing that goes down terribly bad is adding gadgets gizmos and features to make a product look cooler. If a map display does not really aid the main task you try to make people achieve – don’t add it. News show that the site is up to date but can also distract from the real reason the site is there. Photos are fun but are they really needed for a time table application? Don’t think about what can be added but what can be removed. If you can’t remove any more and still make it easy to do what people come for to do you have a winner.
In summary
These are the main problems we found. Overall we had a great time and we were very impressed with both the presentations and the products. I remembered my own school time and I know how scared the presenters must have been. In that regard I have to say great job, guys.

 ';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= '
';
$href = 'http://www.flickr.com/photos/'.$o->nsid.'/'.$a->id;
$out.= ' ';
} else {
$out.= '
';
} else {
$out.= ' ';
}
$out.= '
';
}
$out.= ' ‘.$href.’ – ‘.$o->username.’
‘.$href.’ – ‘.$o->username.’ ';
'; ';
'; ‘;
‘;